Google LLMファミリーのAIモデルをVertexとPythonでファインチューニング
ファインチューニングは、事前学習済みAIモデルをベースにAIモデルを特化させるための強力なツールです。プロンプト方式と比較して、出力精度をさらに向上させることができ、ゼロから新しいAIモデルを開発するよりもはるかにコストを抑えることができます。
この記事では、Google LLMファミリーのAIモデルをVertexとPythonでファインチューニングする方法を詳しく解説します。
さあ、始めましょう!
目次:Pythonを使ったGoogle AIモデルのファインチューニング
AIモデルのファインチューニングとは
AIモデルのファインチューニングとは、事前学習済みのAIモデルを、独自のデータセットを用いてカスタマイズし、精度を向上させるプロセスです。ファインチューニングの目的は、事前学習済みAIモデルの本来のAI機能を維持しつつ、より特殊なユースケースに適合させることです。既存の高度なモデルをファインチューニングによって強化することで、機械学習開発者は特定のユースケースに適した効果的なモデルをより効率的に作成できるようになります。
このアプローチは、計算リソースが限られている場合や関連データが少ない場合に特に有効です。なぜなら、事前学習済みモデルをゼロから作成する必要がないからです。
例えば、あなたがブロガーであり、ソーシャルメディアのコンテンツクリエイターであるとします。モデルを微調整して、あなたのスタイリッシュなトーンでコメントに返信できるようにしたいとします。さらに、独自のトーンで価値提案を盛り込んだブログ記事を書きたいとします。このような場合、微調整はワークフローに統合することでタスクを展開・自動化するための有効な手段となります。
Google AI モデルチューニングのためのデータ準備
Vertex AI 言語セクションのチューニング機能を使用する場合、開発者は JSON データを input_text と output_text という 2 つのキーを使用してフォーマットする必要があります。
開発者はキー名を他のキー名に変更することはできません。
input_text は、プロンプト、コンテキスト、または AI が生成するコンテンツのサンプルを追加するための場所です。一方、output_text は、input_text がプロンプトと類似している場合に AI がどのような応答を期待するかを AI に伝えるための場所です。例えば、ブロガーやソーシャルコンテンツクリエイターの場合、output_text に記事、投稿、その他のコンテンツ形式のサンプル全体を追加できます。
データセットの準備ができたら、Google Vertext AI 言語チューニングに必要な形式である JSON 行に変換する必要があります。
Pandasデータフレームを使用したサンプルは以下のとおりです。
df2.to_json('filename.jsonl', orient='records', lines=True)
pdRead = pd.read_json('yourfilepath.jsonl', lines=True)
モデル作成のチューニング
すべてのデータセットの準備ができたら、Google Cloud Vertexに移行します。
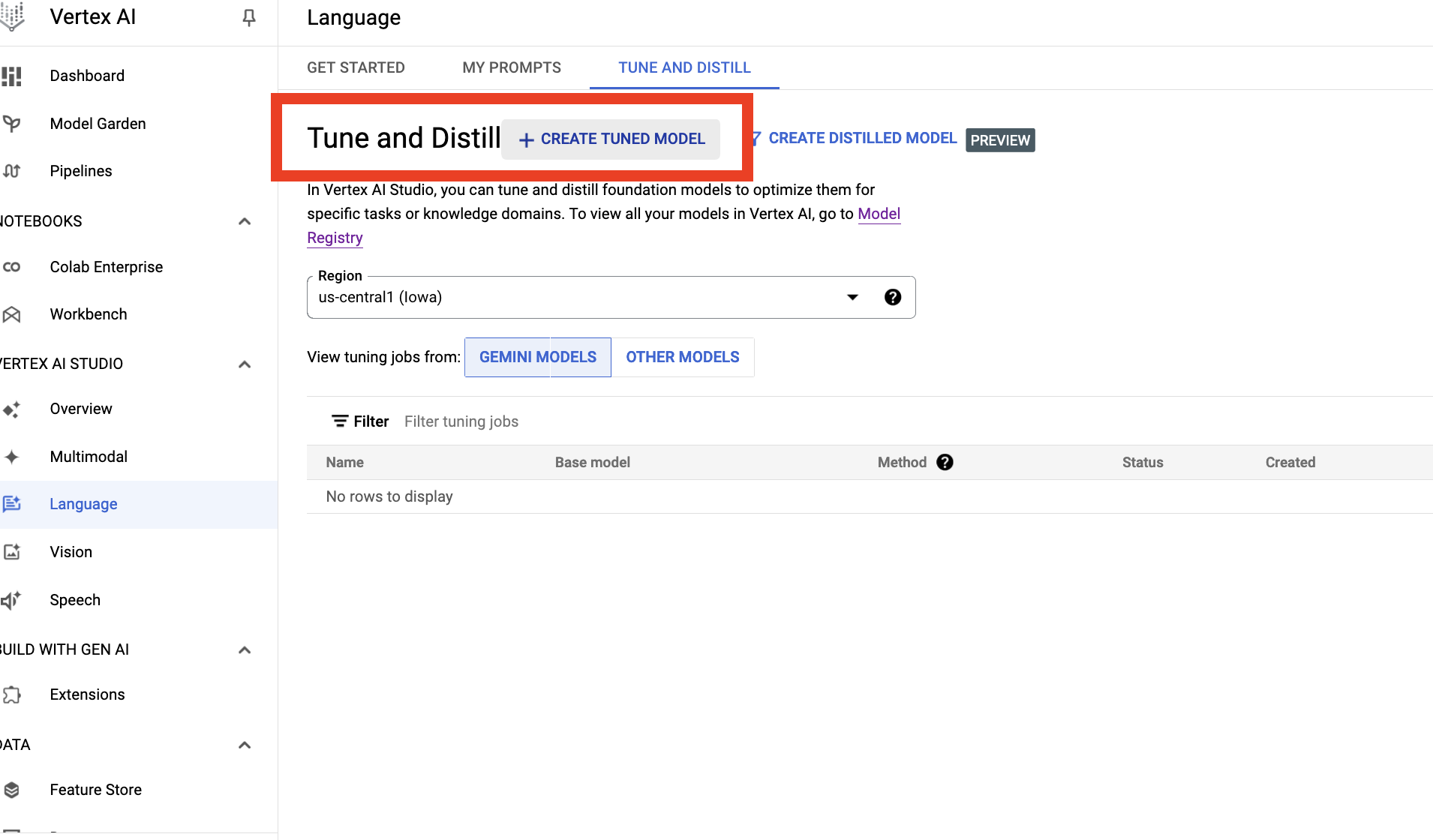
Google Cloudアカウントを作成し、Vertex Studioにアクセスして言語セクションを選択し、以下の画像のように「チューニングと蒸留」タスクを作成します。
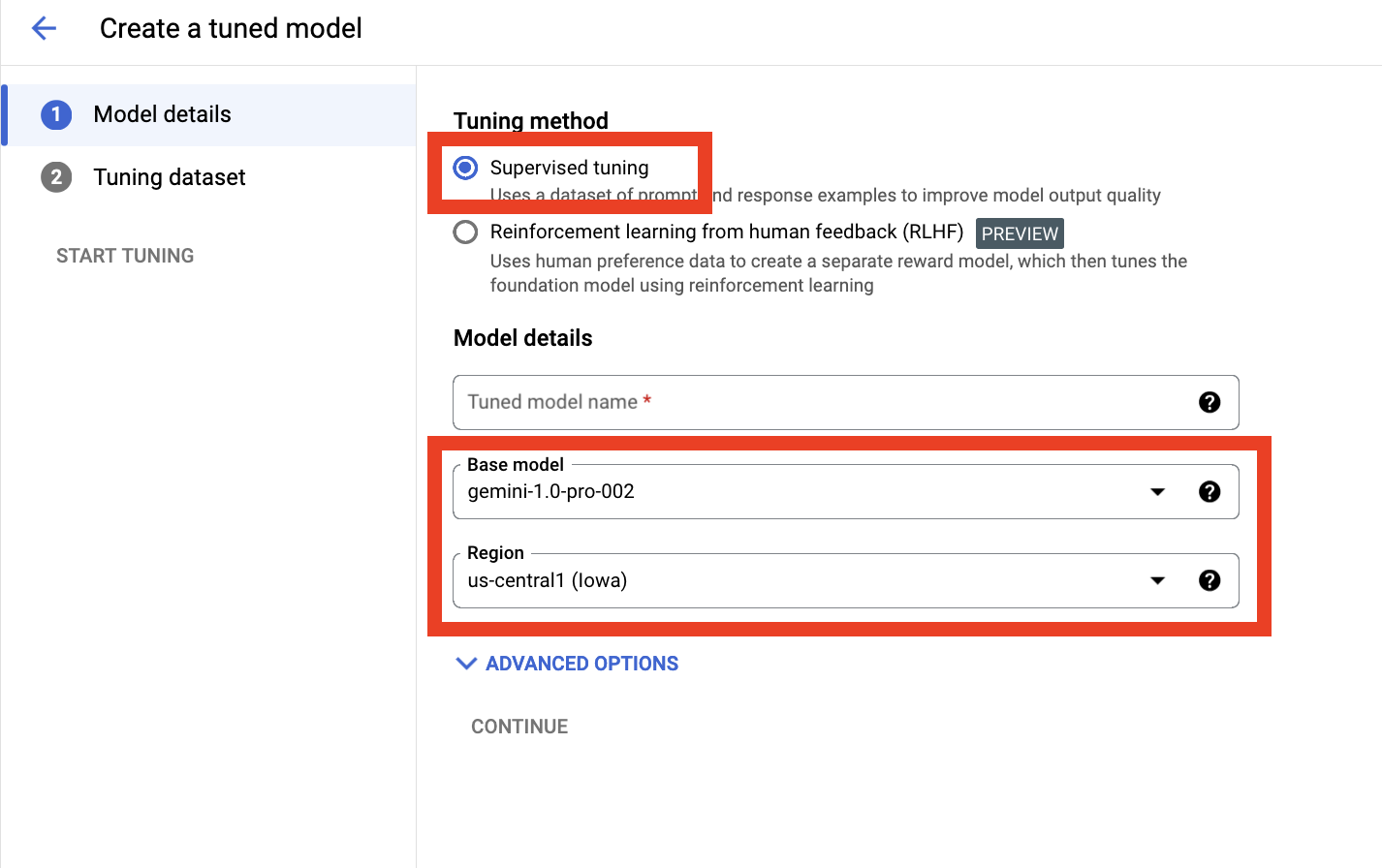
次に、メソッド、モデル、リージョンなどを選択する必要があります。
以下に、教師あり学習モデルであるGeminiとus-centralを示します。
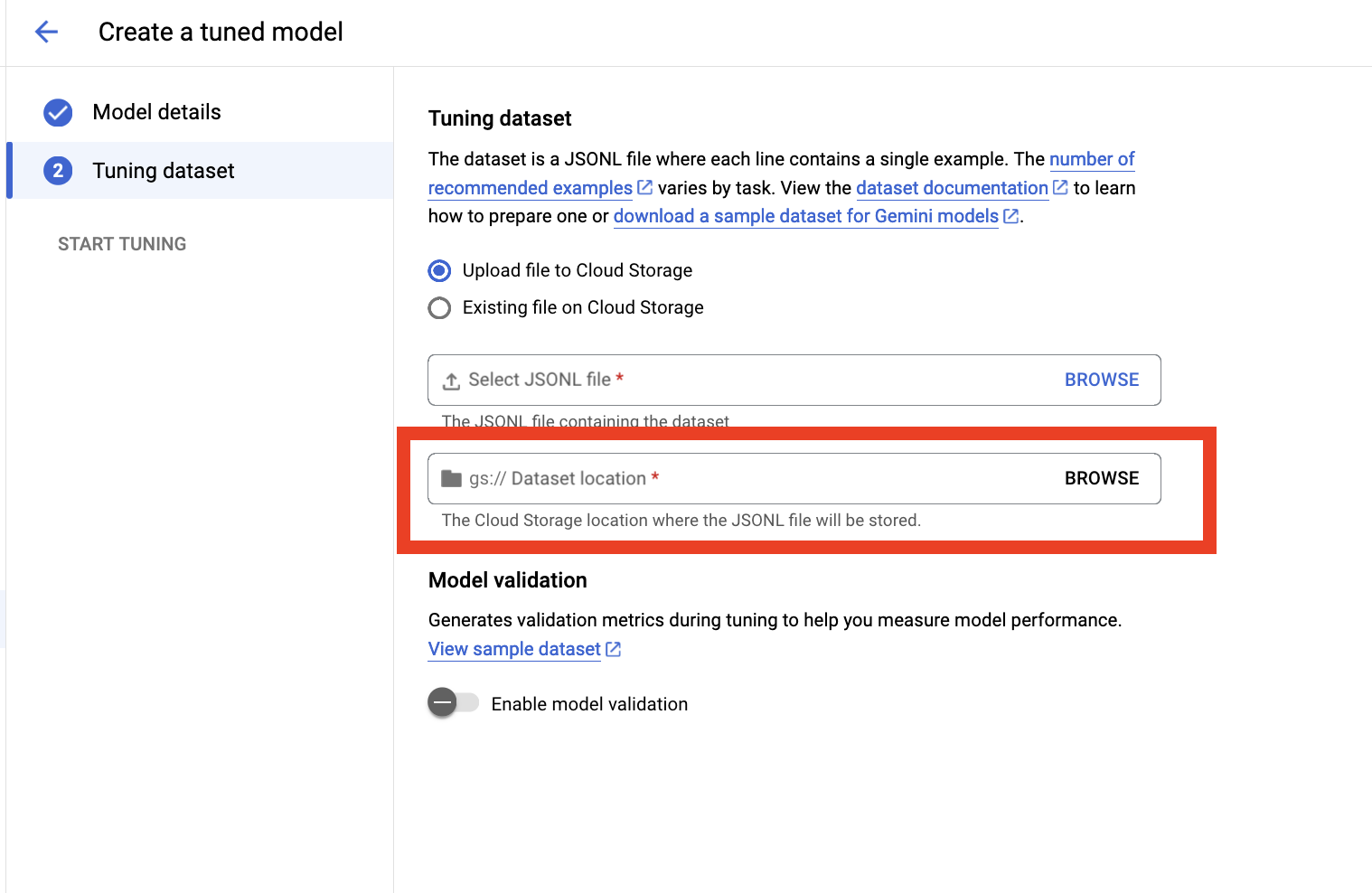
最後に、準備したJSONラインデータセットをGoogle Cloud Storageにアップロードし、ここで選択する必要があります。
チューニング保留中とPythonを使用した呼び出し方法
モデルチューニング中は、パイプラインに移動してステータスを確認したり、言語セクションに戻ってステータスを確認したりできます。所要時間は、事前学習済みモデルのチューニングに使用するデータセットによって大きく異なります。私の場合は、完了までに約5時間かかりました。
チューニングが完了したら、モデルガーデンに移動して、所有データセットを使用してチューニングに使用したモデルをすぐに選択できます。または、Pythonを使用してテストすることもできます。
以下はスクリプトのサンプルです
def tunedModel(self, prompt, characters):
parameters = {
"max_output_tokens": int(characters),
"temperature": 0.9,
"top_p": 1
}
model = TextGenerationModel.from_pretrained("the AI model version")
model222 = model.get_tuned_model("projects/project ID/locations/region name/models/tuned model ID")
response = model222.predict(
prompt,
**parameters
)
return response.text
Google AIモデルチューニングの費用
Vertextのチューニング料金に関する詳細は、Googleで検索し、公式ウェブページで最新情報をご確認ください。
コンテンツ作成を目的としたモデルチューニングにかかる費用についてですが、1回あたり平均100米ドルを費やしています。1回あたりの処理文字数は英語で35万文字、所要時間は約5時間です。これらの数値が、Google AIチューニングの費用に関する参考になれば幸いです。
OpenAIやAzure AIと比較すると、費用はほぼ同程度ですが、場合によってはAzure AIの方が安いこともあります。ケースバイケースです。
まとめ
ファインチューニングは、特定のニッチな目的に特化した、低コストで最先端のAIモデルを実現するための強力なツールです。コストを削減でき、ゼロから開発するための投資も不要です。